
Key Highlights
- Data engineering is very important today. It helps connect raw data to useful insights.
- This toolkit will show you the important tools, technologies, and skills you need to succeed as a data engineer.
- We will look at various resources, from data modeling to cloud computing and security.
- You will find top platforms, languages, and best practices to improve data processes and boost performance.
- This guide is helpful for both beginners and experienced professionals. It gives insights to enhance your skills as a data engineer.
- Use the power of data to make better business decisions with this great toolkit.
Introduction
In today’s world of big data, data engineers play a vital role. Many organizations want to use data to gain insights, especially in data-intensive industries such as healthcare, retail, and financial services. So, there is a high demand for skilled data engineers, making it a highly rewarding career path. Data engineers design, build, and maintain complex systems that gather, process, and analyze large amounts of data using big data tools such as Hadoop or Spark.
The global Big Data and Analytics market is valued at over $348 billion, reflecting the immense growth and investment in data-driven technologies.Additionally, the number of data engineers has more than doubled in recent years, highlighting the increasing demand for this profession. According to LinkedIn’s Emerging Jobs Report, the role of data engineer has seen a year-on-year growth exceeding 30%, underscoring its rapid expansion.
Now, let’s look at the important tools that help data engineers succeed in their work. A data engineer’s toolkit includes many tools and technologies to meet the needs of today’s data management. This toolkit has everything from databases and cloud services to programming languages and tools for data visualization. Knowing how to use these tools is key for doing well in this field. This toolkit looks at a variety of important tools and technologies for data engineers of every skill level. If you are new to data engineering or have been working in this area for a long time, this guide will give you helpful tips to improve your skills and make your data work more efficient. Whether you prefer self-paced learning or structured courses, there are many online courses available to help you develop your data engineering skills, including data transformation tools for adjusting and optimizing disparate data. Additionally, data serving tools are essential for delivering transformed data to end users, such as a BI platform, dashboard, or data science team.
Essential Tools Every Data Engineer Needs
A data engineer’s toolkit includes many tools and technologies to meet the needs of today’s data management. This toolkit has everything from databases and cloud services to programming languages and tools for data visualization. Knowing how to use these tools is key for doing well in this field.
Data engineers need a comprehensive toolkit to effectively manage and process data. These tools range from data modeling and integration platforms to advanced analytics and cloud computing services. The data engineering tools market is projected to grow significantly, reaching $89.02 billion by 2027, up from $43.04 billion in 2022, highlighting the increasing reliance on specialized tools to streamline data processing and enhance efficiency.
1. Comprehensive Guide to Data Modeling Tools
Data modeling is key for good data management and analysis. It is about designing how data is organized, how it connects, and what limits it has in a database system. Data modeling tools help show and explain data setups. They keep data consistent and help find information quickly.
There are different tools for various data modeling needs. Some are for high-level designs, while others are for specific database platforms. The global data modeling software market is projected to reach a significant size by 2032, reflecting a robust compound annual growth rate (CAGR) from 2024 onwards. This growth is driven by the increasing demand for effective data management solutions across various industries. Knowing how to use these tools helps data engineers make strong and flexible data models.
Some popular data modeling tools are ERwin Data Modeler, Oracle SQL Developer Data Modeler, and MySQL Workbench. Using these tools helps data engineers manage data sets, raise data quality, and make data integration smoother. The proliferation of industry-specific models and increased use of conceptual modeling are trends that will gain traction as businesses seek more efficient ways to manage data. Additionally, data modeling tools are essential for bridging the gap between technical and non-technical stakeholders, promoting better understanding and collaboration.
2. Top Data Integration and ETL Platforms
Data integration is important for changing raw data from different sources into a clear and useful format for analysis. ETL (Extract, Transform, Load) platforms play a key role in building better data pipelines that make this process easier. The global ETL software market was valued at approximately $3.1 billion in 2021 and is projected to reach $10.3 billion by 2030, growing at a compound annual growth rate (CAGR) of 14.3% during the forecast period.This growth is driven by the increasing volume and complexity of data, the rising popularity of cloud-based solutions, and the need for real-time data processing.
These platforms offer a full set of tools for:
- Extracting data from many sources, like databases, APIs, and cloud storage.
- Transforming data into a standard format, while cleaning and checking it.
- Loading data into target systems, such as data warehouses or data lakes, for analysis.
Some well-known ETL platforms are Apache Airflow, Informatica PowerCenter, and Talend Open Studio. These tools help data engineers automate data flows, enhance data quality, and ensure quick delivery of data for business intelligence and decision-making. The demand for cloud-based ETL solutions is also increasing, as they offer scalability, ease of use, and cost-effectiveness, making them an attractive choice for businesses migrating their data and workloads to the cloud. The Asia-Pacific region is expected to experience substantial growth in the ETL software market, driven by the increasing adoption of cloud computing and the growing demand for real-time data processing.
3. Essential Databases for Modern Data Engineering
Choosing the right database system is very important for good data storage and retrieval. Data engineers need to know different types of database technologies, such as:
- Relational databases (SQL) like PostgreSQL, MySQL, and Oracle are great for storing structured data. They keep data in tables with clear relationships. These databases are known for their data integrity and consistency, which makes them good for transaction systems.
- NoSQL databases are flexible for handling unstructured or semi-structured data. They provide high scalability and availability. Popular choices include MongoDB, Cassandra, and Redis. These are ideal for managing large amounts of data with different structures.
The global database management system market is projected to reach $142.5 billion by 2027, growing at a compound annual growth rate of 12.9% from 2020 to 2027. This growth is driven by the increasing demand for efficient data management solutions and the proliferation of data across various industries. More than 60% of corporate data is now stored in the cloud, emphasizing the importance of cloud-based database solutions. Additionally, cloud adoption among enterprise organizations is over 94%, with many businesses leveraging cloud-based databases for their scalability and cost-effectiveness. When data engineers understand both SQL and NoSQL systems well, they can choose the best technology for each specific case. This helps ensure good performance and scalability.
4. Advanced Analytics and Machine Learning Libraries
Data engineering is more than just traditional data management. It also connects with machine learning and artificial intelligence. Machine learning libraries help create models that can make predictions and find hidden patterns in data.
Python is a leading language in data science and machine learning. It has many libraries, such as scikit-learn, TensorFlow, and PyTorch. These libraries provide different algorithms and tools for tasks like classification, regression, clustering, and deep learning. The global machine learning market is projected to grow significantly, reaching $209.91 billion by 2029, with a compound annual growth rate (CAGR) of 38.8% from 2022 to 2029. This growth is driven by the increasing adoption of machine learning across various industries, including finance, healthcare, and retail, where it is used for applications such as fraud detection, patient monitoring, and demand prediction. The natural language processing market is also expected to grow from $26.42 billion in 2022 to $161.81 billion by 2029.
Data engineers who have machine learning skills can build predictive analytics solutions. They can automate decisions based on data and help make AI-powered applications. The integration of advanced analytics is anticipated to drive the global advanced analytics market from $52.33 billion in 2023 to over $913.07 billion by 2036, growing at a CAGR of 24.6%.
5. Data Visualization Tools for Impactful Insights
Data visualization is important. It helps change complex data into easy-to-understand insights that help in making business decisions. A good visualization can show trends, outliers, and patterns that may be hidden in raw data. The global data visualization tools market was valued at $9.22 billion in 2022 and is expected to grow at a compound annual growth rate (CAGR) of 11.4% from 2023 to 2030, reaching $22.12 billion by 2030.
Data visualization tools provide many chart types, dashboards, and interactive features. These tools make it easy to explore data and share findings. They support data-driven decisions in an organization.
Some popular choices are Tableau, Power BI, and Qlik Sense. These tools help data engineers and business intelligence analysts create strong visualizations that clearly show insights. The ability to quickly and effectively communicate information through visual means is increasingly important, with data visualization playing a vital role in big data analytics by transforming complex datasets into visual representations that are easy to understand and interpret.
6. Cloud Computing Services for Scalable Data Solutions
Cloud computing has changed how organizations save, handle, and study data. It gives them the ability to grow, be flexible, and save money like never before. Data engineers use cloud platforms to create strong and scalable data systems. The global cloud computing market is expected to grow significantly, with a forecasted value of $947.3 billion by 2026, reflecting a compound annual growth rate (CAGR) of 16.3% through 2026.
This growth is driven by the increasing adoption of cloud services across various industries, as organizations seek to enhance their IT infrastructure and improve operational efficiency. Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure are the leading cloud providers, with AWS holding a 32% market share, followed by Azure at 23%, and Google Cloud at 11%. The cloud will host more than 100 zettabytes of data by 2025, which will be equivalent to 50% of the world’s data at that time. This shift underscores the critical role of cloud computing in data engineering, as more than 60% of corporate data is now stored in the cloud. The widespread adoption of cloud services is further evidenced by 96% of companies using at least one public cloud, and 92% employing a multi-cloud strategy.
7. Version Control Systems for Collaborative Development
Version control systems are very important for software development. They also help a lot in data engineering. These systems keep track of changes in code, settings, and data models. This makes it easier for people to work together, manage their code, and recover from problems.
Git is a popular version control system used by both developers and data engineers. According to a survey, 93% of developers use Git, highlighting its dominance in the version control market. The global version control system market was valued at $897.2 million in 2019 and is expected to grow at a compound annual growth rate of 12.6% from 2020 to 2026, reaching $2.04 billion by 2026. Websites like GitHub, GitLab, and Bitbucket help with teamwork by offering features for code storage, tracking issues, and managing projects.
For data engineers, using version control is key. It keeps their code safe, makes working together simpler for the team, and allows them to go back to older code if they need to.
8. Containerization and Orchestration Technologies
Containerization and orchestration technologies are gaining popularity in data engineering, offering portability, scalability, and efficient resource utilization. Containers package applications with all their dependencies, ensuring consistency across different environments. The global application container market is projected to grow from $3.77 billion in 2024 to $29.70 billion by 2031, at a compound annual growth rate of 25.87%. Docker is a well-known containerization platform that helps data engineers build portable and self-sufficient applications. Kubernetes, an orchestration platform, automates tasks like deploying, scaling, and managing containers. Kubernetes has become a mainstream technology, with 96% of organizations either using or evaluating it as their preferred container platform. The global container orchestration market was valued at $450.5 million in 2023 and is anticipated to reach $1.196 billion by 2030, reflecting its growing importance in managing complex containerized environments. By leveraging containerization and orchestration, data engineers can simplify deployment, optimize resource usage, and enhance the scalability of their data pipelines. The adoption of serverless containers is also on the rise, with 46% of container organizations now running serverless containers, up from 31% two years ago. As more organizations migrate to containerized environments, these technologies will continue to play a crucial role in modern data engineering practices.
9. Monitoring and Logging Tools for Operational Excellence
Continuous monitoring and logging are very important for keeping data pipelines running well. These tools help us see how the system is doing and find any issues quickly, which helps in fixing problems and making things better. Monitoring tools show real-time data and send alerts about important system numbers. Logging tools collect detailed info about what happens in the system and any errors. The global log management market is expected to grow from $2.3 billion in 2020 to $4.1 billion by 2026, at a compound annual growth rate (CAGR) of 11.2%. This growth highlights the increasing importance of monitoring and logging in maintaining system performance and reliability. Centralized logging groups logs from different sources to make it easier to analyze and solve issues. Some popular tools for data engineering are Prometheus, Grafana, and the ELK Stack (Elasticsearch, Logstash, and Kibana). The ELK Stack, for instance, has been downloaded millions of times and is the most popular log management platform globally, while Splunk, another leading platform, reports having 15,000 customers. These tools help data engineers keep data pipelines working smoothly and at high performance. Prometheus and Grafana are particularly well-suited for monitoring the performance of microservices and cloud-native systems, offering a powerful combination for metrics collection and visualization. As organizations increasingly rely on complex data systems, the demand for robust monitoring and logging solutions is expected to continue growing, ensuring operational excellence and minimizing downtime.
10. Security and Compliance Tools for Data Protection
Data security and compliance are paramount in today’s data-driven world. Data engineers are responsible for implementing security measures and adhering to regulatory requirements throughout the data lifecycle. The global data protection market size was valued at $131.82 billion in 2023 and is projected to grow to $505.98 billion by 2032, exhibiting a compound annual growth rate of 16.4% during the forecast period.
Data security tools encompass a wide range of solutions for:
- Data encryption: Protecting sensitive data at rest and in transit.
- Access control: Managing user permissions and restricting access to authorized personnel.
- Vulnerability scanning: Identifying and mitigating potential security risks.
- Data masking: Obfuscating sensitive data for development and testing purposes.
|
Tool/Technology |
Description |
|
AWS Key Management Service (KMS), Google Cloud Key Management Service (KMS), Azure Key Vault |
Encryption key management |
|
Identity and Access Management (IAM) services (AWS IAM, GCP IAM, Azure IAM) |
Access control |
|
Security Information and Event Management (SIEM) tools |
Log analysis and threat detection |
Data compliance tools help organizations adhere to industry-specific regulations, such as GDPR, HIPAA, or PCI DSS. These tools often include features for data governance, data discovery, and compliance reporting. These tools often include features for data governance, data discovery, and compliance reporting.The data-centric security market, which focuses on protecting data through its entire lifecycle, was valued at $4.2 billion in 2022 and is expected to grow at a CAGR of 23.9% from 2023 to 2028.
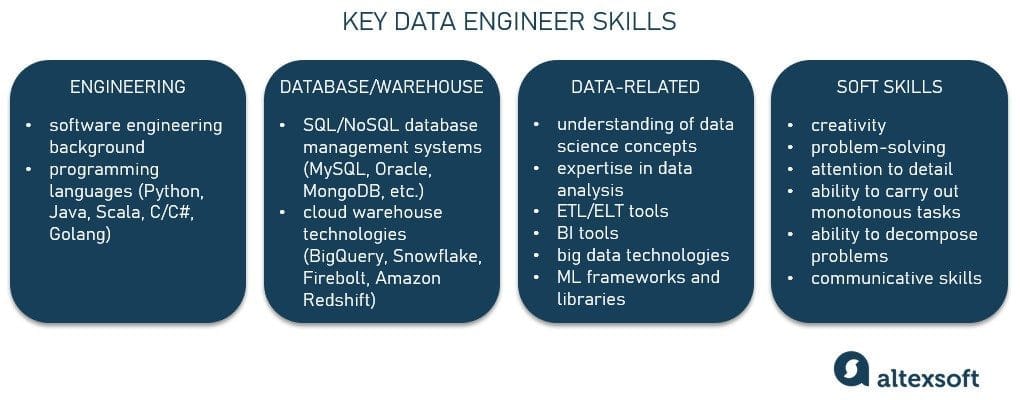
Building the Foundation: Core Skills for Data Engineers
Data engineers need a strong foundation in technical skills to design, build, and maintain robust data systems. These skills include programming languages, database management, and a solid understanding of data architecture. According to the U.S. Bureau of Labor Statistics, employment for database administrators and architects is expected to grow by 8% from 2022 to 2032, which is faster than the average for all occupations. This growth underscores the increasing demand for professionals with database management skills. Additionally, data engineering jobs are projected to grow by 21% from 2018 to 2028, with about 284,100 new jobs expected over the next decade. These statistics highlight the promising career prospects and the critical role of data engineers in today’s data-driven world.
11. Mastering SQL and NoSQL Databases
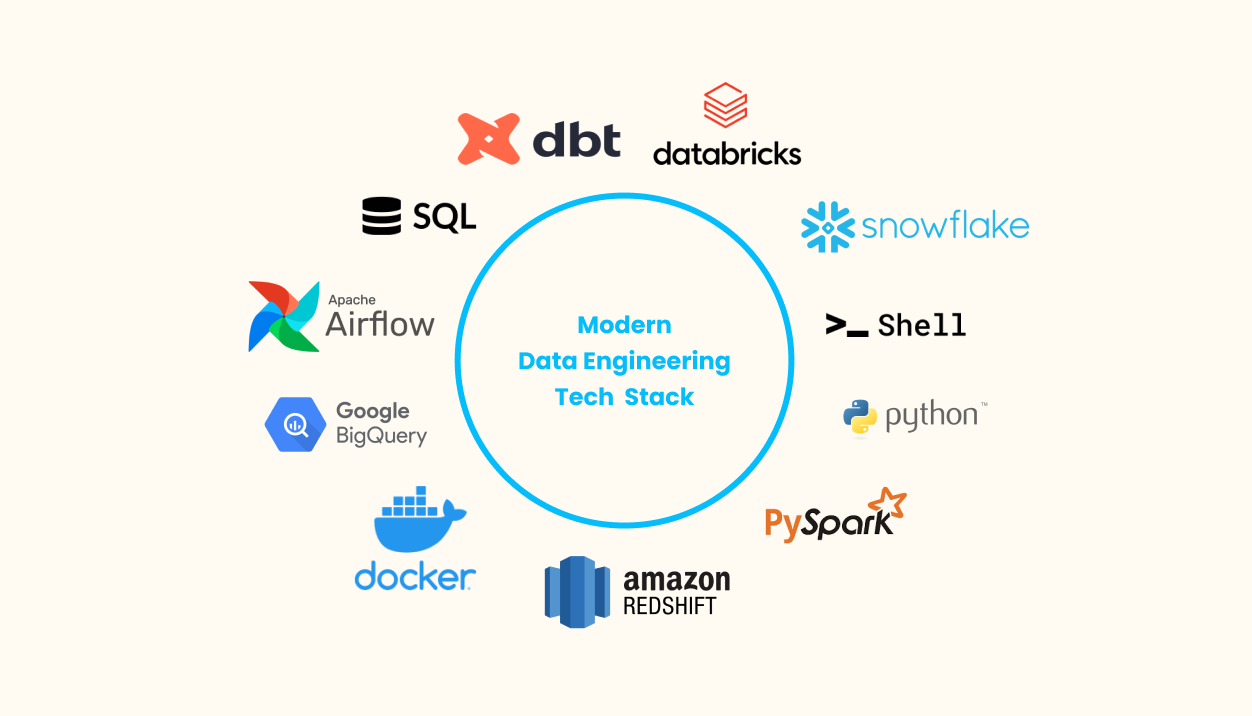
Proficiency in SQL (Structured Query Language) and NoSQL databases is very important for data engineers who work with relational databases. SQL helps with querying, managing, and changing data in relational database management systems (RDBMS). A survey found that SQL skills are required in nearly 80% of data engineering job postings. NoSQL databases, such as MongoDB and Cassandra, are also important for storing and managing structured or unstructured data based on specific requirements. It is also important to understand database normalization, indexing, and query optimization. These skills help with fast and effective data retrieval and manipulation, especially when using data warehousing tools such as Amazon Redshift, Google BigQuery, and Snowflake.
Knowing about NoSQL databases is also key. As data volume and variety grow, NoSQL databases give flexibility and scalability. They help in handling unstructured or semi-structured data but need a different way to model and query data.
Data engineers need to understand both SQL and NoSQL databases. They should know the good and bad points of each to make the best architectural choices, whether they are working on traditional systems or large data pipelines.
12. Proficiency in Programming Languages: Python, Scala, Java
Programming skills are very important for a data engineer. Python is a popular choice because it is easy to read and has many libraries. People often use Python to manage data, to write scripts, and to create data pipelines. Python is used in approximately 70% of data engineering roles.
Scala is another strong language used for big data. It pairs well with Apache Spark for processing data in distributed environments. Its short code and focus on functions make it good for transforming large sets of data.
Java is also widely used in data engineering, especially within big data systems like Hadoop. Data engineers choose Java for tasks that need high efficiency, the ability to handle many processes at once, and to connect with other systems.
13. Understanding of Data Architecture Principles
A good understanding of data architecture is important for creating data systems that work well, can grow, and are easy to manage. Data engineers must know different ways to model data, concepts of data warehousing, and how to integrate data.
It is also vital to understand data governance principles, data quality management, and metadata management. According to a survey, 77% of organizations cited data-driven decision-making as a leading goal, emphasizing the importance of high-quality data and robust data architecture. This knowledge helps keep data reliable, stable, and accurate through all stages of its lifecycle.
Data architecture includes not just technology. It involves understanding how data moves within a company. This means finding data sources, defining data types, and designing data pipelines that fit business needs.
14. Expertise in Big Data Technologies: Hadoop, Spark
As organizations deal with growing amounts of data, knowing big data technologies is very important for data engineers. Apache Hadoop is a leader in processing data in a distributed way. It helps store and process large datasets using everyday hardware.
Apache Spark is a fast and flexible computing system. It has become popular because it is speedy, easy to use, and can connect with different data sources. Spark is mentioned in 41.1% of data engineering job postings, while Hadoop appears in 17.8%, highlighting their significance in the field. Spark can do in-memory processing. This makes it great for running repeated algorithms and analyzing data in real time.
Data engineers who know Hadoop and Spark can build and manage data processing pipelines. They can use the power of parallel processing and tackle the issues that come with big data analytics.
Advanced Techniques and Best Practices
Data engineers can do more than just the basics. By using advanced techniques and best practices, they can make data pipelines work better, increase efficiency, and provide high-quality data. This section will look at ways to automate data pipelines, process data in real-time, and use artificial intelligence and machine learning to help people get even more value from their data. According to a report by McKinsey, companies that leverage data-driven decision-making are 23 times more likely to acquire customers, six times as likely to retain customers, and 19 times as likely to be profitable.
15. Automating Data Pipelines for Efficiency
Data pipeline automation is very important. It helps to simplify data tasks, cut down on manual work, and boost overall efficiency. When we automate repetitive jobs like data extraction, transformation, and loading, data engineers can spend more time on important tasks.
Workflow orchestration tools, like Apache Airflow, offer a way to set up, schedule, and track complex data pipelines. These tools let data engineers create directed acyclic graphs (DAGs). These graphs show how data is connected and help automate tasks.
Automation saves time and reduces the risk of human mistakes. This leads to data pipelines that are more dependable and easy to repeat. According to Gartner, organizations that automate their data pipelines can reduce operational costs by up to 30%. It also helps data engineers build strong data infrastructure that can adjust to new business needs.
16. Implementing Real-Time Data Processing
Real-time data processing is becoming very important. Companies want to get insights from data that is constantly changing. Streaming data platforms help data engineers process data as it comes in. This allows them to use real-time analytics and make quick decisions.
One popular choice is Apache Kafka. It is a streaming platform that handles a lot of data efficiently. It helps with getting, processing, and sharing streaming data. Data engineers use Kafka to create real-time applications, send data to data lakes or warehouses, and take actions based on real-time events. The global streaming analytics market is projected to grow from $27.84 billion in 2024 to $185.08 billion by 2032, highlighting the increasing demand for real-time data processing solutions.
With the ability to manage streaming data, organizations can do so much more. They can respond to events as they happen. This helps them gain valuable insights and make smart decisions quickly.
17. Leveraging AI and Machine Learning for Data Insights
The mix of artificial intelligence and machine learning with data engineering opens up new ways to get valuable insights from data. By using these techniques in data pipelines, data engineers can make decision-making automatic, improve data quality, and boost data analysis skills.
Machine learning can improve data quality. It does this by finding and fixing errors, filling in missing values, and spotting unusual trends. These algorithms learn from past data to make predictions, find patterns, and give important insights that are hard for people to see.
As AI and ML improve, data engineers who use these technologies will lead in innovation. They will create smart data pipelines. This helps their organizations make better and faster data-driven decisions. According to IDC, global spending on AI systems is expected to reach $300 billion by 2026, reflecting the growing importance of AI and ML in data-driven decision-making.
18. Data Governance and Quality Management
Data governance and quality management are very important parts of data engineering. They help keep data accurate, consistent, and trustworthy. When organizations use data governance policies, procedures, and standards, they can manage their data better. This also helps them follow rules and meet compliance requirements.
Data quality management means putting processes in place for checking data, fixing errors, and ensuring it is correct. This makes sure the data is accurate, complete, and reliable. When organizations keep data quality high, they can make better decisions using trustworthy data. According to a study by IBM, poor data quality costs the U.S. economy around $3.1 trillion annually, highlighting the critical need for effective data governance and quality management practices.
Data engineers have an important role in using data governance frameworks and data quality processes. They help make sure data is handled with care, meets set standards, and allows for reliable analysis and decision-making.
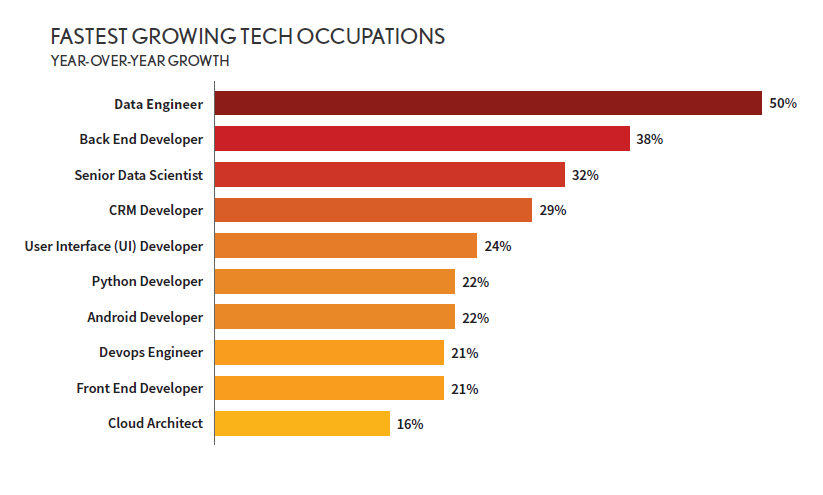
Conclusion
In summary, the right toolkit for a data engineer includes important tools and skills needed to succeed in data engineering. You should know how to model data and use integration platforms. It is also essential to understand advanced analytics and cloud computing services. Building a strong base in SQL, programming languages, and data architecture is key. Plus, learning techniques like automating data pipelines and processing data in real-time will help you a lot. By adding these skills to your set, you can enhance your knowledge and play an important role in data-driven projects. The demand for data engineers is expected to grow significantly, with projections indicating a 21% increase in job opportunities from 2018 to 2028, resulting in approximately 284,100 new jobs. This growth reflects the increasing reliance on data-driven decision-making across industries. Furthermore, the global big data market is anticipated to reach $745.15 billion by 2030, emphasizing the critical role of data engineers in managing and leveraging large datasets. Make sure to stay updated with the latest technologies and best practices to keep up in the changing world of data engineering.
References:
- https://www.youtube.com/user/snowflakecomputing
- https://cloud.google.com/dataflow/
- https://www.glassdoor.com/Salaries/analytics-engineer-salary-SRCH_KO0,18.htm
- https://www.instagram.com/splunk/
- https://medium.com/codex/4-reasons-why-data-engineering-is-a-great-career-move-in-2022-3ef07b1e14f3
- https://www.bls.gov/ooh/computer-and-information-technology/database-administrators.htm#tab-6
- https://www.cloudera.com/more/training/certification/ccp-data-engineer.html
- https://www.computerweekly.com/feature/How-to-get-structure-from-unstructured-data
- https://www.datacamp.com/courses/introduction-to-data-engineering